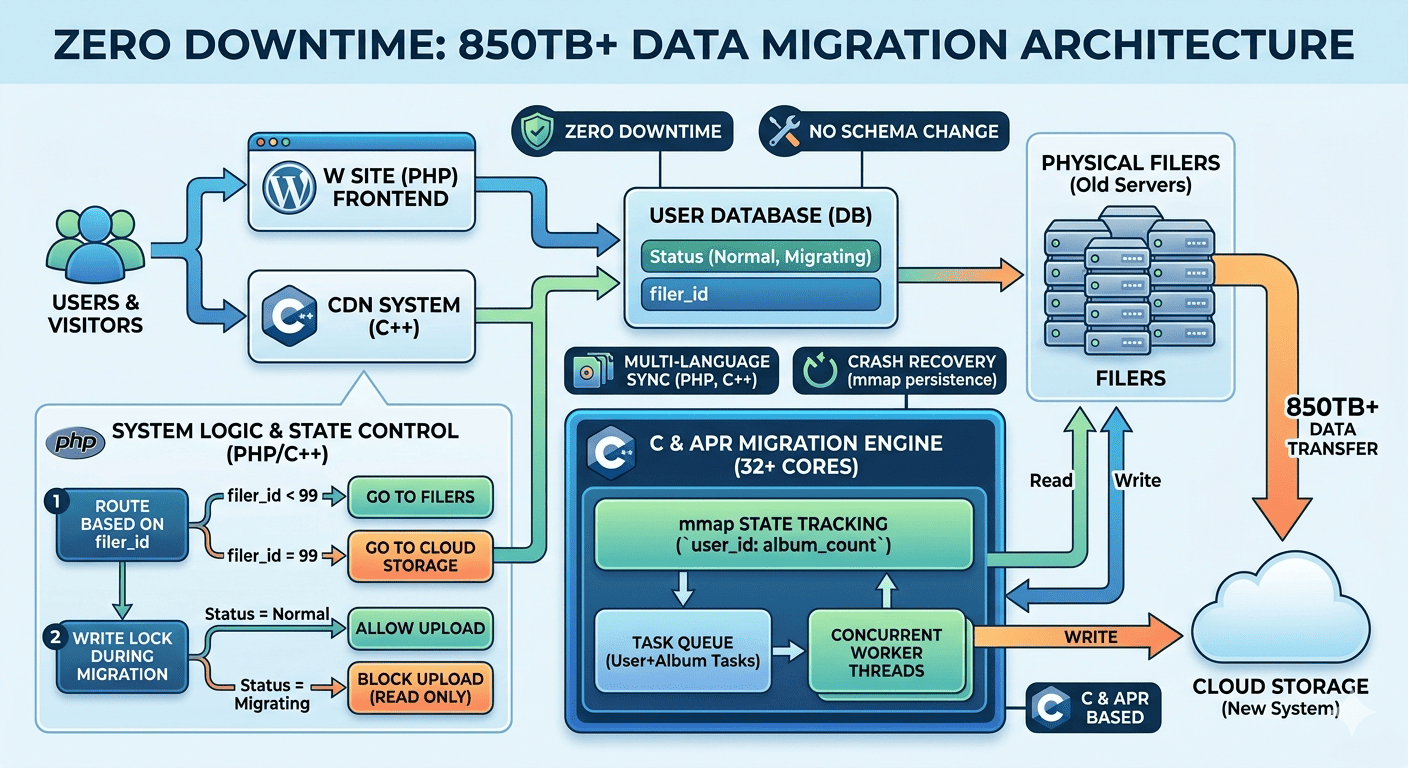
緣起:在高速公路上替換賽車引擎 Link to heading
回溯至 2011 年左右,W 小站面臨了一項極限任務:我們必須在 完全不影響服務(Zero Downtime) 的情況下,完成大規模底層架構變革。外界對此幾乎毫無察覺,但對內部團隊而言,這是一場在極速行駛中替換引擎的硬仗。 當時的核心架構中,由於使用者的照片數量極其龐大,單一檔案伺服器(Filer)無法承載所有數據,因此系統是由多台 Filer 分散負載。而在資料庫設計上,使用者資料表中有一個特定欄位,專門用來記錄該使用者存放於哪一座 Filer 上,藉此進行存取導向。
核心目標:搬遷至 Cloud Storage Link to heading
這項工程的最終目的,是將分散在各個 Filer 的海量相片,全數移轉至公司內部的 Cloud Storage(性質類似現在的 AWS S3)。然而,這看似單純的搬遷任務,卻面臨了三個極其苛刻的限制:
- 零停機維護(Zero Downtime) 當時流量價值極高,營運團隊下令:搬遷過程中,服務必須保持 100% 在線,不允許任何停機時間。
- 禁止變更資料庫結構(No Schema Change) 由於使用者資料量龐大,在當時環境下,任何 Schema 的微小改動都可能導致長波段鎖表(Table Lock)。因此,我們必須在「不新增、不修改」現有欄位的情況下完成搬遷。
- 異質語言架構的邏輯一致性(Multi-language Environment) 前端網頁主要由 PHP 編寫,但內部 CDN 系統則是以 C++ 實作。遷移方案必須同時在兩套截然不同的環境下完美同步,絕不能出現定位錯誤。
方案評估:為什麼「直觀方法」行不通? Link to heading
在動手實作前,我們評估並捨棄了以下幾種常見方案:
- 物理層同步 (Physical Mount / Rsync): Filer 與 Cloud Storage 的檔案結構不一致,直接拷貝無效,且搬遷時的頻寬競爭會干擾前端存取。
- 網路檔案系統掛載 (NFS Mount): 跨機房延遲極高,且 NFS 在網路不穩時容易產生 hung processes,極大機率導致 Web Server 崩潰當機。
- 使用者層級檔案系統 (FUSE - curlhttpfs): 效能完全無法達標,且錯誤處理邏輯與架構不符,易造成系統無回應。
實作策略:在既有框架中尋找「活路」 Link to heading
我們最終決定在「應用程式邏輯層」解決問題:
- 虛擬 Filer:以「99」作為雲端代碼
我們利用現有的
filer_id欄位定義了虛擬 Filer:
- 邏輯轉向: 指定
99代表 Cloud Storage。 - 跨語言同步: PHP 與 C++ 偵測到 filer_id = 99 時,自動將 Cloud Storage 設定為 Origin Server。
- 優點: 避開 Schema Change,對資料庫來說只是極速的整數更新。
- 遷移狀態機:利用「停權欄位」建立寫入鎖(Write Lock) 搬遷中最怕「邊搬邊改」。我們複用了原有的使用者狀態欄位:
- 定義新狀態: 增加「移轉中(Migrating)」狀態。
- 讀寫分離:移轉中的使用者暫時禁止上傳(確保資料靜態),但訪客瀏覽(讀取)完全不受影響。
- 工具選擇:以 C 與 APR 打造搬遷引擎 選用純 C 語言開發搬遷引擎,並以 APR 為框架:
- Memory Pool: 確保大規模運行下能徹底釋放資源,解決 Memory Leak 的後顧之憂。
- 多執行緒並發與任務粒度(Multithreading & Unit) 在當時 32 核(Cores)以上的硬體環境下,若採單執行緒運行會極大浪費資源。我們決定利用 APR + Thread 實作並發,但隨即面臨了任務單位(Unit)的抉擇:
- 抉擇:以「使用者」還是「相簿」為單位? 若以「使用者」為單位,會產生嚴重的「長尾效應」。一個擁有一萬本相簿的重度用戶,其寫入鎖定時間可能長達數小時,嚴重影響體驗。
- 最終方案:以「相簿」為任務單位的追蹤機制
- 掃描與註冊: 計算用戶相簿總數
album_count。 - Mmap 狀態共享: 將
user_id: album_count寫入 mmap (Memory-mapped file) 檔案,供多執行緒高效率讀寫。 - 任務分發: 將
user_id + album_id丟進 Thread Queue,由 Worker Threads 搶佔。 - 遞減與完工: 每完成一本相簿,mmap 中的
album_count減 1。歸零時,判定該用戶搬遷完畢。 - 解鎖與切換: 自動恢復用戶狀態,並將
filer_id切換為99。
- 掃描與註冊: 計算用戶相簿總數
- 韌性設計:如何在崩潰中生存?(Error Handling) 在大規模遷移中,Process 崩潰是必然。我們設計了多層保護:
- Unix Signal 捕捉: 捕捉
SIGINT,SIGTERM,SIGSEGV等訊號。收到訊號時,程式會嘗試將目前正在搬遷的使用者從「移轉中」解鎖,避免用戶被永久鎖死。 - mmap 持久化(Crash Recovery):
由於 mmap 對應實體檔案,即便進程崩潰,剩餘進度仍留在磁碟中。
- 策略:重啟工具後,程式會讀取 mmap 檔案,找出所有尚未歸零的 user_id。
- 簡單即美: 由於 mmap 僅記錄 album_count,無法得知具體哪些相簿已完成,我們採取了「全部從頭重跑」的策略。對於單一使用者來說,這確保了資料的一致性,且邏輯最為單純穩健。
戰果:850TB+ 搬遷後的意外洞察 Link to heading
最終,我們成功將 850TB+ 的海量檔案全數搬入 Cloud Storage。在過程中,我們也證實了現實環境遠比理論複雜:
- 極端案例 (Edge Case): 雖然我們預期單個相簿多在 100~200 張照片,但實際掃描發現最極端的案例是單一相簿內放了約 3 萬張照片。
- 應對: 雖然這讓該用戶的處理時間顯著拉長,但得益於我們設計的「以相簿為單位」的並發處理,單一超大相簿僅會佔用一個執行緒,而不會阻塞整個搬遷引擎。
結語:穩定高於一切的工程實踐 Link to heading
這項工程最成功的表現,就在於它的寂靜。數百萬用戶在照常分享生活的同時,底層架構已悄悄完成了跨世代的演進。這不只是技術上的勝利,更是對系統工程師精神的最好實踐。
聊聊您的技術挑戰 Link to heading
我們 Embark Systems 提供專業的軟體顧問服務,特別擅長處理底層整合與效能最佳化。如果您有相關需求,歡迎隨時與我們 聯絡詳談,讓我們用積累多年的技術經驗,為您的專案打造最合適的解決方案。